Post-Training Beats Frontier: Scaling RNJ-1 to 256 GPUs with ScalarLM
March 11, 2026 · Training · Scaling · Open Telco AI
One of the most persistent debates in applied ML is whether domain post-training can close the gap with large frontier models. The GSMA Open Telco AI leaderboard — launched last week as part of a new global initiative to build telco-grade AI in the open — provides some of the cleanest evidence yet that it can. And the results were produced using ScalarLM running on AMD MI325X GPUs at TensorWave.
Here's what we observed, and what it took to get there.
The Result: Open Models Outperform Frontier on Telco Tasks
The GSMA leaderboard evaluates models across four dimensions specific to telecom operations: correctness, faithfulness, relevancy, and abstention accuracy. These are not synthetic benchmarks. They reflect the kind of precision required for real network operations — interpreting standards documentation, diagnosing faults, answering domain-specific queries without hallucinating protocol details that don't exist.
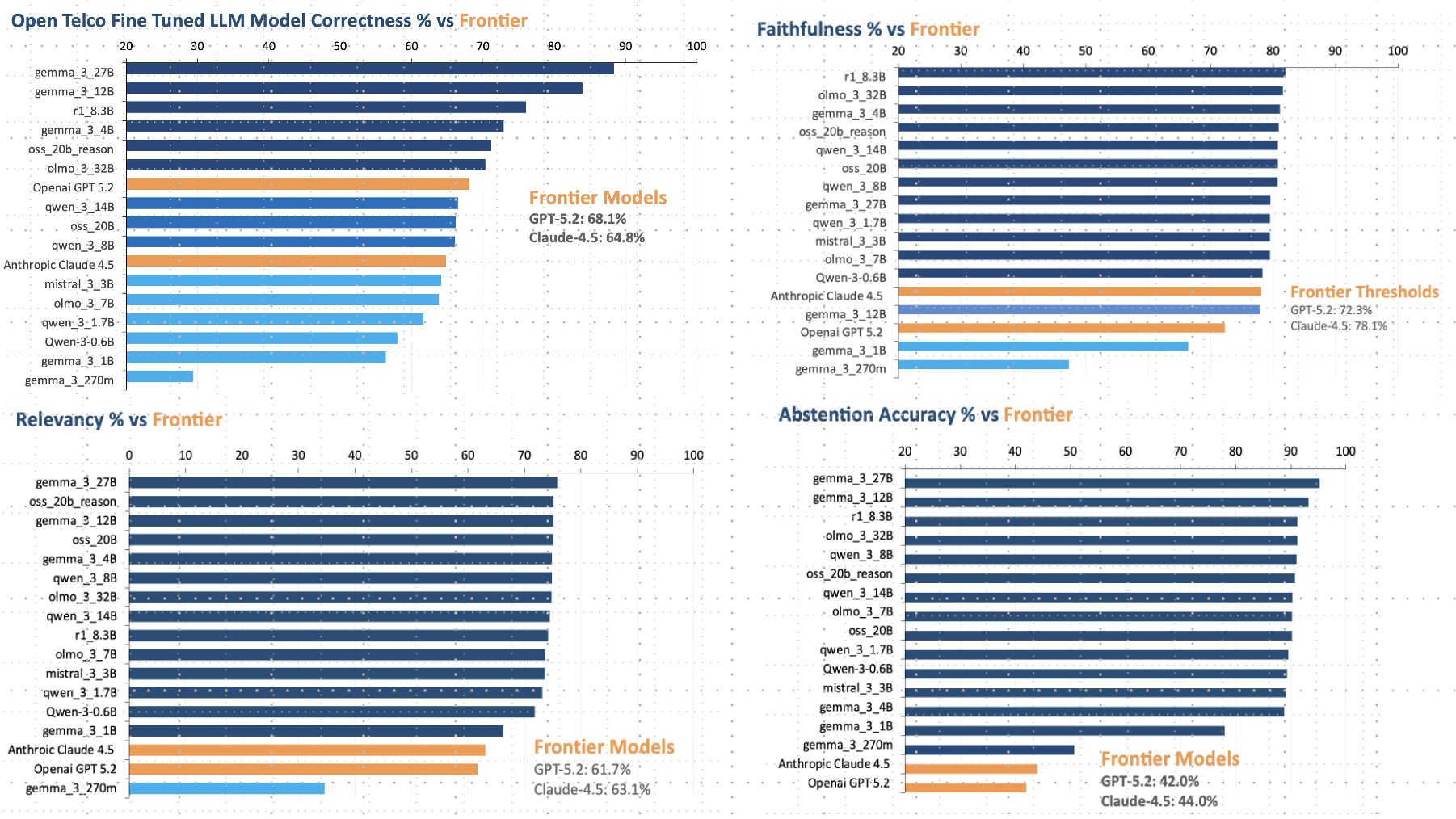
The headline numbers for the frontier baselines are GPT-5.2 at 68.1% correctness and Claude-4.5 at 64.8%. These are strong, well-resourced models with broad world knowledge. And yet post-trained open models — Gemma 3 27B, Gemma 3 12B, r1 8.3B — consistently exceed them on correctness, with several models landing in the 65–75% range despite being a fraction of the size.
The abstention accuracy numbers tell an even sharper story. Frontier models score in the low 40s — GPT-5.2 at 42.0%, Claude-4.5 at 44.0%. Open post-trained models cluster in the high 80s and low 90s. The practical implication is significant: a network operations model that refuses to hallucinate a nonsense answer when it doesn't know something is far more deployable than one that confidently provides a wrong one. Post-training on domain data doesn't just improve task accuracy — it calibrates model uncertainty in ways that generic RLHF on general data does not.
The result that stands out most to us is the faithfulness score distribution. Frontier models anchor around 72–78%. Many of the post-trained open models cluster tightly in the 80–88% range, suggesting that alignment to telco-specific facts is genuinely learnable from relatively small amounts of domain data, and that it is not a property of model scale alone.
The Scaling Run: 94.2% Efficiency at 256 GPUs
To produce results at this level, you need to be able to scale training efficiently. The weak scaling benchmark for RNJ-1 on AMD MI325X hardware, run using ScalarLM on TensorWave infrastructure, shows what that looks like in practice.
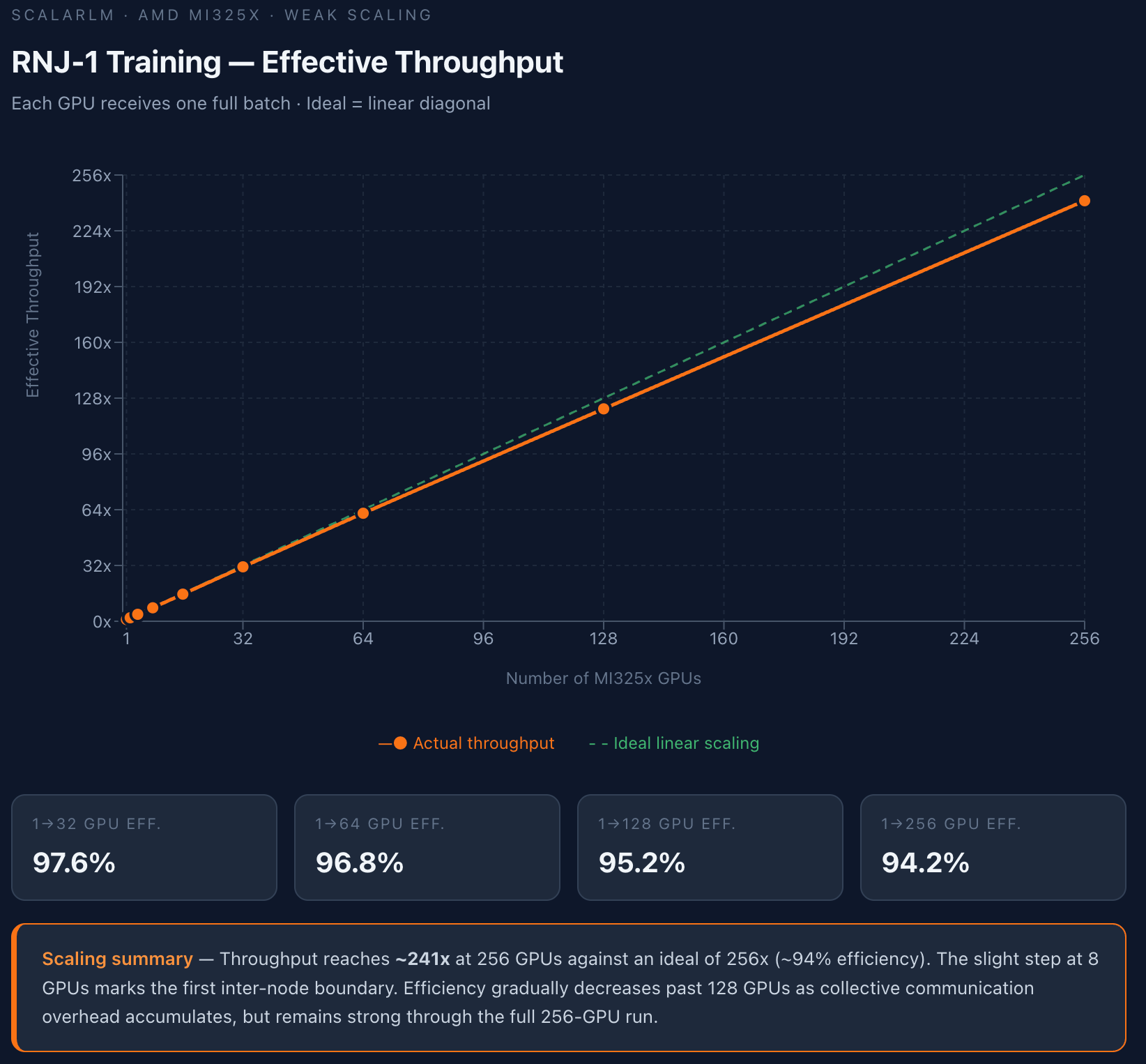
In a weak scaling setup, each GPU receives one full batch — so the ideal outcome is exactly linear: doubling the number of GPUs should double total throughput, with no degradation. The results track near-ideal across the full range:
| Scale | Efficiency |
|---|---|
| 1 → 32 GPUs | 97.6% |
| 1 → 64 GPUs | 96.8% |
| 1 → 128 GPUs | 95.2% |
| 1 → 256 GPUs | 94.2% |
At 256 GPUs, measured throughput reaches approximately 241x relative to a single GPU, against an ideal of 256x. The slight step visible at 8 GPUs corresponds to the first inter-node boundary — the point at which communication leaves the NVLink/xGMI fabric and enters the network interconnect. Past 128 GPUs, collective communication overhead accumulates gradually, but the curve remains impressively close to linear through the full 256-GPU run.
A few things are worth noting about what makes this result meaningful rather than just a benchmark number:
It was measured on AMD MI325X hardware, not NVIDIA. The majority of published training scaling curves are on NVIDIA A100 or H100. This result demonstrates that near-linear scaling behavior is achievable on AMD hardware with the same Megatron-LM distributed training infrastructure that ScalarLM exposes. For labs evaluating hardware diversity as an infrastructure strategy, this is relevant evidence.
The efficiency holds at the inter-node boundary. The 8-GPU step is visible but small. The collective communication patterns in Megatron-LM's tensor parallelism implementation handle inter-node transitions gracefully, and the ScalarLM deployment's Kubernetes + Slurm scheduling layer does not introduce meaningful overhead on top.
94.2% at 256 GPUs is a practical working number, not a cherry-picked peak. This is the kind of efficiency you need to be able to count on when scheduling multi-day training jobs. A system that achieves 99% efficiency on a 16-GPU test but degrades to 80% at 128 GPUs is not useful for real research workloads.
Why This Matters for Domain Post-Training Research
The combination of these two results — a leaderboard showing post-trained models beating frontier, and a scaling curve showing near-linear throughput to 256 GPUs — points to something researchers should find interesting.
The telco results suggest that for narrow-domain tasks with well-defined correctness criteria, the data efficiency of post-training is high enough that you don't need to scale model size to compete with frontier. What you need is the ability to run enough training iterations, on good domain data, on a model with sufficient baseline capability (RNJ-1's architecture is specifically designed for post-training extensibility). The ScalarLM workflow — local ml/ directory customization, automatic upload with job submission, no rebuild required — is designed to make that iteration loop as short as possible.
At the same time, the scaling curve matters because training budget is not unlimited, and faster iteration at scale means more experiments per unit time. A lab running ablations over loss function design, data mixture ratios, or optimizer configuration can run those experiments on 64–128 GPUs with high confidence that the result will extrapolate linearly to 256 if the winning configuration merits a larger run.
Context: GSMA Open Telco AI
The leaderboard results are part of the GSMA Open Telco AI initiative, launched on March 2, 2026 at MWC Barcelona. The initiative is a coordinated effort to build open-weight, open-data, hardware-agnostic AI infrastructure for the telecom industry — a sector where, according to GSMA Intelligence data, only 16% of GenAI deployments have been applied to network operations, largely because general-purpose models fail on the precision and calibration that telecom tasks require.
TensorWave and AMD are founding compute partners, providing the GPU infrastructure and open toolchain for training, fine-tuning, and evaluation. ScalarLM is the training and inference stack running on that infrastructure.
The leaderboard itself is available at the GSMA Hugging Face Space. Models can be submitted and evaluated against the seven telco-specific benchmarks. If you are working on domain adaptation for network operations, standards interpretation, or fault diagnosis, this is a directly relevant evaluation framework with a clear path from your training run to a published result.
Running Your Own Post-Training Experiment
If you want to replicate or extend this work, the path through ScalarLM is straightforward:
import scalarlm
scalarlm.api_url = "https://gemma3_4b_it.farbodopensource.org"
llm = scalarlm.SupermassiveIntelligence()
# Load your telco domain dataset
dataset = load_telco_dataset("path/to/telco_finetuning_data.jsonlines")
status = llm.train(
dataset,
train_args={
"max_steps": 500,
"learning_rate": 3e-4,
"gpus": 64,
"dtype": "bfloat16",
}
)
To customize the training loop — swap the optimizer, modify the loss function, adjust the data pipeline — check out the ml/ directory in the ScalarLM repository. Any changes you make locally are automatically uploaded with your next job submission.
To push the resulting checkpoint to the GSMA leaderboard or your own Hugging Face repository, see the Save Post-Trained Model to Hugging Face guide.
The GSMA Open Telco leaderboard results are a concrete example of what the ScalarLM stack was built to enable: taking a capable open base model, applying domain post-training efficiently at scale, and producing a result that beats closed frontier models on the metrics that matter for the target application. The scaling curve shows the infrastructure side of that equation is sound up to 256 GPUs on AMD hardware. The rest is research.