ScalarLM Benchmarking MI300X Memcpy Peer
This blog covers the performance of the MI300X GPU in the context of a memcpy peer benchmark.
Here are the specs of the MI300X GPU for reference:
- HBM: 192GB HBM3E
- HBM Bandwidth: 5.3 TB/s
- Infinity Fabric Link Bandwidth: 50 GB/s
- Infinity Fabric Links Per GPU: 7
- BF16 Compute: 1.3 PFLOP/s
- FP8 Compute: 2.6 PFLOP/s
Memcpy peer is used to measure the memory bandwidth when copying data between two different GPUs on the same node. Memcpy peer is a good indicator of collective operations such as all-reduce, all-gather, and scatter-reduce. Collective operations are used to distribute LLMs across multiple GPUs. The performance of these operations is critical for training and inference of large language models.
MI300X Intra-Node Network Architecture
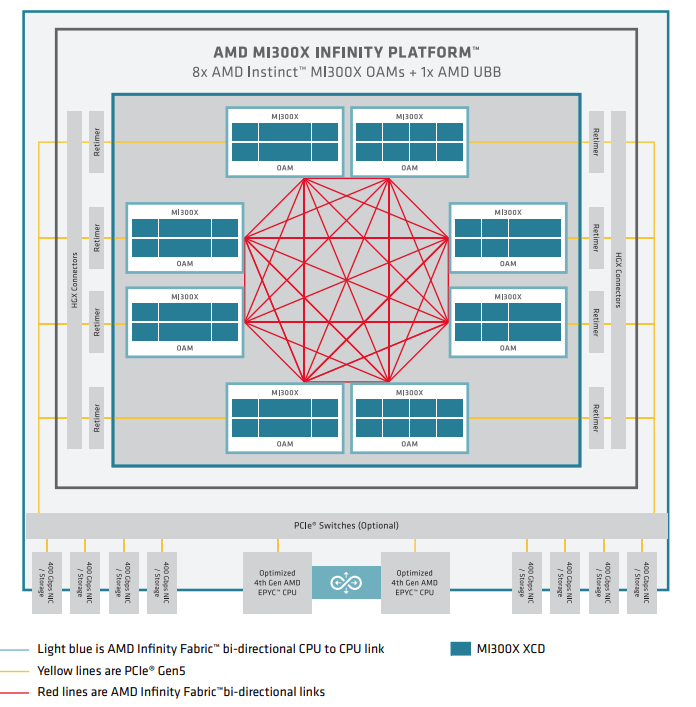
Looking at the diagram, we can see eight MI300X DAMs (Discrete Accelerator Modules) arranged in an octagonal configuration, interconnected via AMD's Infinity Fabric. The red lines illustrate the direct GPU-to-GPU Infinity Fabric links, forming a fully connected mesh topology where each GPU maintains direct connections to all other GPUs in the system. This design eliminates multi-hop communication paths, allowing any GPU to communicate with any other GPU through a single direct link with the full 50 GB/s bandwidth per link.
This architecture significantly enhances GPU-to-GPU peer performance for memory transfers. With each GPU having a direct 50 GB/s Infinity Fabric link to every other GPU, memcpy peer operations—which directly impact collective operations like all-reduce, all-gather, and scatter-reduce—can achieve optimal performance. The fully connected topology minimizes latency by eliminating the need for data to traverse through intermediate GPUs or the CPU, which would otherwise create bottlenecks in collective operations. This is particularly crucial for distributed training and inference of large language models where frequent synchronization between GPUs is required.
Benchmark Results
This figure plots memcpy peer bandwidth against the size of the data being copied. The x-axis is the size of the data being copied in bytes, and the y-axis is the bandwidth in GB/s.
The data is copied from one location in one GPU's memory to another location in another GPU's memory. We use PyTorch to show the performance of the memcpyPeer API. We also show GPU-aware MPI_Send and MPI_Recv for comparison.
The benchmark is run for different sizes of data, ranging from 4KB to 2.1GB, which is the size of the embedding tables in the Llama 3.1 8B model.
PyTorch Memcpy Peer Benchmark
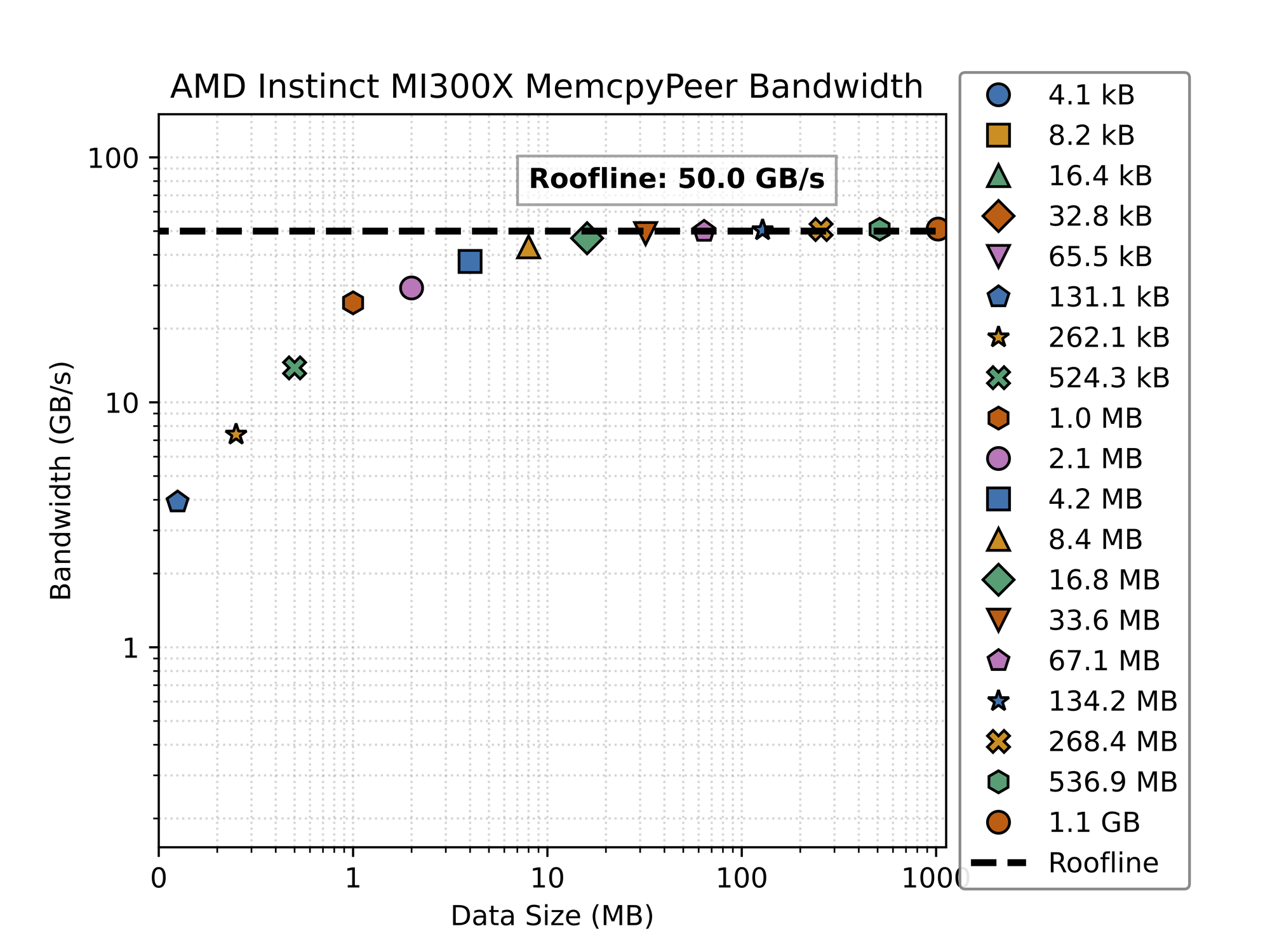
The benchmark results for the AMD MI300X MemcpyPeer bandwidth demonstrate clear scaling patterns across different data transfer sizes. As shown in the logarithmic plot, the achieved bandwidth starts at just a few GB/s for very small transfers (below 100KB) and gradually increases with data size until reaching the theoretical maximum of 50 GB/s (marked as the "Roofline" on the graph) at approximately the 8-16MB range. This scaling behavior illustrates the classic relationship between data transfer size and bandwidth utilization, where small transfers are dominated by fixed overheads while larger transfers can more effectively saturate the available bandwidth.
The results reveal that the MI300X Infinity Fabric links reach near-optimal performance (above 40 GB/s) once transfer sizes exceed approximately 8MB, with the bandwidth curve flattening as it approaches the 50 GB/s roofline. This indicates that the communication protocol and hardware implementation have been well-optimized to minimize overhead for large data transfers. The bandwidth stabilizes completely for transfers larger than 32MB, suggesting that at this point, the system fully leverages the available bandwidth of the Infinity Fabric link without additional scaling benefits from increasing the data size further.
Most notably, the bandwidth curve shows a dramatic improvement between 100KB and 10MB data sizes, where performance increases from approximately 10-15 GB/s to over 40 GB/s. This critical transition zone represents an important threshold for application developers and system architects, as it determines the minimum message size needed to achieve efficient communication between MI300X GPUs. Understanding this threshold is essential for optimizing collective operations in distributed AI workloads, where the granularity of data partitioning can significantly impact overall system performance.
Key Learnings:
- Bandwidth Saturation Point: The MI300X Infinity Fabric links reach approximately 90% of theoretical bandwidth at 8-16MB transfer sizes, indicating the minimum message size for optimal communication efficiency.
- Small Transfer Penalty: For data transfers smaller than 1MB, bandwidth utilization drops significantly, with 100KB transfers achieving only about 20% of peak bandwidth. This suggests a need for message aggregation strategies in applications dealing with small data blocks.
- Near-Linear Scaling Region: The log-log plot reveals a near-linear scaling region between 100KB and 8MB, where each doubling of message size yields substantial bandwidth improvements, making this range particularly sensitive to optimization efforts.
- Protocol Efficiency: The ability to achieve very close to the theoretical 50 GB/s limit demonstrates excellent protocol efficiency with minimal overhead for large transfers, indicating well-designed hardware and driver implementations.
- Implications for AI Workloads: For distributed training of large language models, these results suggest that tensor partitioning strategies should aim for partition sizes of at least 16MB to ensure optimal GPU-to-GPU communication performance across the Infinity Fabric interconnect.
The performance characteristics demonstrated in these benchmarks validate AMD's fully connected topology approach for the MI300X platform. The ability to consistently achieve near-theoretical bandwidth between directly connected GPUs confirms that the direct GPU-to-GPU links can effectively eliminate communication bottlenecks in multi-GPU configurations, provided that applications are structured to leverage appropriate transfer sizes. For HPC and AI system architects, these results highlight the importance of data partitioning strategies that maximize message sizes while maintaining computational efficiency across the distributed system.
MPI Memcpy Peer Benchmark
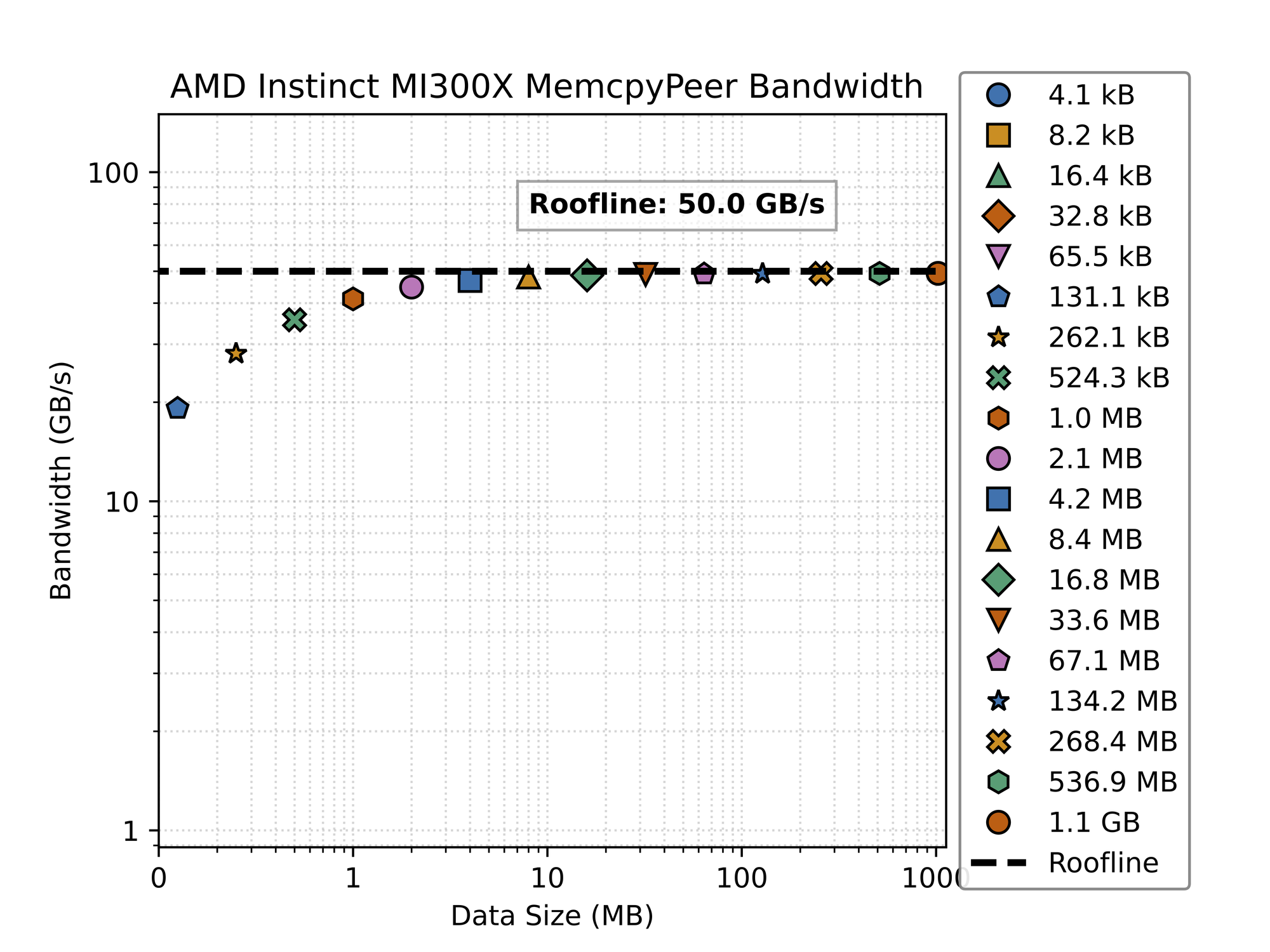
MPI has lower overheads than PyTorch, achieving 40GB/s with 1MB transfers instead of 8MB transfers for PyTorch.
This benchmark demonstrates the bandwidth performance of AMD's MI300X GPU using MPI_Send and MPI_Recv operations across a 50 GB/s Infinity Fabric link.
The graph shows a clear bandwidth saturation pattern. For small data transfers (below 10MB), the achieved bandwidth is significantly lower than the theoretical maximum of 50 GB/s. However, as data size increases beyond 10MB, the bandwidth approaches and eventually reaches the theoretical roofline of 50 GB/s. This indicates that the MI300X requires larger message sizes to efficiently utilize the full bandwidth capacity of the Infinity link, which is typical of high-performance interconnects where protocol overhead dominates with smaller transfers.
What's particularly notable is the steep bandwidth curve between 1-10MB message sizes, where performance rapidly improves from approximately 12 GB/s to nearly 40 GB/s. Beyond 16.8MB (represented by the green diamond), almost all data points cluster near the 50 GB/s roofline, showing that the system efficiently utilizes the available bandwidth for larger data transfers. The largest tested size of 1.1GB achieves essentially full utilization of the link.
Key Insights:
- Bandwidth Saturation Point: The MI300X requires approximately 16.8MB message size to reach ~80% of theoretical bandwidth, and 33.6MB to achieve >90% utilization of the Infinity link.
- Small Message Inefficiency: Transfers below 4.2MB achieve less than 50% of the theoretical bandwidth, with the smallest sizes (4.1kB) managing only about 4% utilization. This highlights the significant protocol overhead for small transfers.
- Logarithmic Scaling: The consistent improvement across logarithmic increases in data size suggests well-designed network protocols that efficiently handle varying workloads.
- Practical Performance Threshold: HPC applications should batch communications to exceed 16.8MB when possible to maximize bandwidth utilization on the MI300X.
- Interconnect Ceiling: The hard limit at 50 GB/s confirms that the single Infinity link is the bottleneck rather than the GPU memory subsystem, suggesting that multi-link configurations would be beneficial for bandwidth-sensitive applications.
These benchmark results provide valuable guidance for HPC developers optimizing communication patterns on MI300X-based systems, particularly highlighting the importance of message size on achievable performance when using MPI point-to-point operations.
Cache Effects
This benchmark does not flush caches or use cache bypass instructions, so it is measuring the performance of the entire memory subsystem including caches.
We would expect caches to give a performance benefit for small transfer sizes that can fit in the L2 cache and be reloaded without needing to be fetched from HBM or the peer GPU.
This is balanced against the overhead of small transfers. From these results, performance never exceeds the link bandwidth of 50GB/s, meaning that overheads dominate for sizes that fit in the caches.
PyTorch Benchmark Code
You can find the benchmark code on the ScalarLM Peer Memcpy Github.
Let's take a look at the code:
Memcpy Sizes
# List of memcpy sizes, in bytes, should be multiples of the page size
# Go up to the tensor size used in Llama 3 (4096 * 128256 * 4) = 2_101_346_304
memcpy_sizes = [ 2 ** i for i in range(12, 64) if 2 ** i <= 2_101_346_304 ]
This code sets up the sizes of the data to be copied. The sizes are powers of 2, starting from 4KB (2^12) and going up to
1.1GB (2^30). The sizes are chosen to be multiples of the page size, which is 4KB on most systems. The maximum size is
the size of the embedding tables in the Llama 3 8B model, which is 2_101_346_304 bytes (or 2.1GB). The benchmark is run for
each of these sizes, and the bandwidth is measured for each size. The results are plotted in the figure above.
Benchmark Setup
Next, we set up the benchmark:
def run_memcpy_benchmark():
warmup()
results = {}
for size in tqdm(memcpy_sizes):
results[size] = run_memcpy(size)
return results
This function runs the memcpy benchmark. It first warms up the GPU by running a few iterations of the memcpy kernel
without measuring the time. This is done to ensure that the GPU is in a good state before running the benchmark. The
function then runs the memcpy kernel for each size in the memcpy_sizes list and measures the time taken to copy the data.
Warmup
Warmup is pretty simple.
def warmup():
run_memcpy(4096)
This function runs the memcpy kernel with a size of 4KB (4096 bytes) to warm up the GPU. GPUs have startup times to
load the code, ramp up the clocks, etc. Running benchmarks without a warmup can lead to misleading results.
Running Memcpy Peer PyTorch
The run_memcpy function is where the actual memcpy kernel is run. It uses PyTorch to allocate memory on the GPU and copy data from one location to another. The source and destination tensors are allocated on different GPUs. The function measures the time taken to copy the data and calculates the bandwidth
and other metrics.
The memcpy kernel is run for at least 1 second to get a good measurement of the bandwidth. The function uses PyTorch'scopy_ method to copy data from one tensor to another. copy_ is the in-place version of the copy method, which means
that it modifies the destination tensor in place. This is more efficient than creating a new tensor for the result because it avoids
allocating memory for the result tensor.
def run_memcpy(size):
a = torch.zeros(size // 4, device=get_device(), dtype=torch.float32) # size is in bytes, so divide by 4 to get number of floats
b = torch.zeros(size // 4, device=get_device(), dtype=torch.float32)
# copy for at least 1 second
barrier()
start = get_event()
end = get_event()
start_time = time.time()
start.record()
iterations = 0
while time.time() - start_time < 1:
b.copy_(a)
iterations += 1
end.record()
barrier()
total_time = start.elapsed_time(end) * 1e-3 / iterations
return {
"operational_intensity": 1 / 4, # 1 FLOP per 4 bytes
"flop/s": size / 4 / total_time,
"bytes": size,
"time": total_time,
"iterations": iterations,
"bandwidth": size / total_time,
"GB/s": size / total_time / 1e9,
}
Handling GPUs
When running on a GPU, the benchmark uses PyTorch's CUDA events to measure the time taken to copy the data. CUDA events are
used to measure the time taken to execute a kernel on the GPU. The record method is used to record the time at which
the event is recorded. The elapsed_time method is used to calculate the time taken to execute the kernel. The time
is measured in milliseconds, so we multiply by 1e-3 to convert to seconds. Using events is necessary because the GPU
is asynchronous, meaning that the CPU and GPU can run in parallel. The CPU can continue executing while the GPU is
copying data. This can lead to misleading results if the time taken to copy the data is not measured correctly.
In order to make the code cross-platform, we define a get_event function that returns a CUDA event if the GPU is available, or a CPU event
if the GPU is not available. The CPU event is a simple wrapper around the time module that records the time when the event is created and
calculates the elapsed time between two events.
class CPUEvent:
def __init__(self):
self.time = 0
def record(self):
self.time = time.time()
def elapsed_time(self, other):
return (other.time - self.time) * 1000
def get_event():
if torch.cuda.is_available():
return torch.cuda.Event(enable_timing=True)
else:
return CPUEvent()
def barrier():
if torch.cuda.is_available():
torch.cuda.synchronize()
else:
pass
def get_device():
if torch.cuda.is_available():
return torch.device("cuda:0")
else:
return torch.device("cpu")
MPI Benchmark Code
You can find the MPI benchmark code on Github.
We use a custom GPU-aware openmpi build in ScalarLM that allows using MPI operators directly on PyTorch tensors.
from gpu_aware_mpi import send, recv, barrier, get_rank, get_size, finalize_mpiThis is necessary to make sure that our MPI build is linked against PyTorch, ROCm, SLURM, and the ROCe network driver.
Each MPI rank manages one GPU. One GPU sends the tensor, and the other receives it.
def send_recv(sendbuf, i):
sender = i % 2
rank = get_rank()
barrier()
if rank == sender:
send(sendbuf, (rank + 1) % 2)
else:
recv(sendbuf, (rank + 1) % 2)
barrier()